
ITIL Problem Management – 1
Problem Management is an absolute requirement for any company interested in reducing the number of incidents occurring in their environment and help us in minimising the impact of Incidents that cannot be prevented.
Problem Management is responsible for managing the lifecycle of all problems.
An example
Say your laptop battery is not working properly & your laptop isn’t working without any battery backup. This is an incident because it disrupted the
service working on something. You fix it by keeping it connected with the charger for the time that you are working. This way you are able to work on your laptop. But now, there is a problem- you always have to keep the laptop connected to charger if you intend to work.
To fix the problem, you need to change the battery of laptop.
Normally, an incident needs to be fixed within a specific timeline. Problems can be left indefinitely until an incident happens.
How problem management works
In
Problem management, we use analysis techniques to identify the cause of the problem. For Incident management, we find the cure so that services are restored. Thus, Problem management takes longer and should be done once the urgency of the incident has been dealt with: for example, removing a faulty office laptop and replacing it with a working spare laptop by IT Helpdesk, takes the urgency away and leaves the faulty laptop ready for repair.
Problem management can take time but within limits to lessen the cost of resolution.
Steps in Problem Management
Step 1:
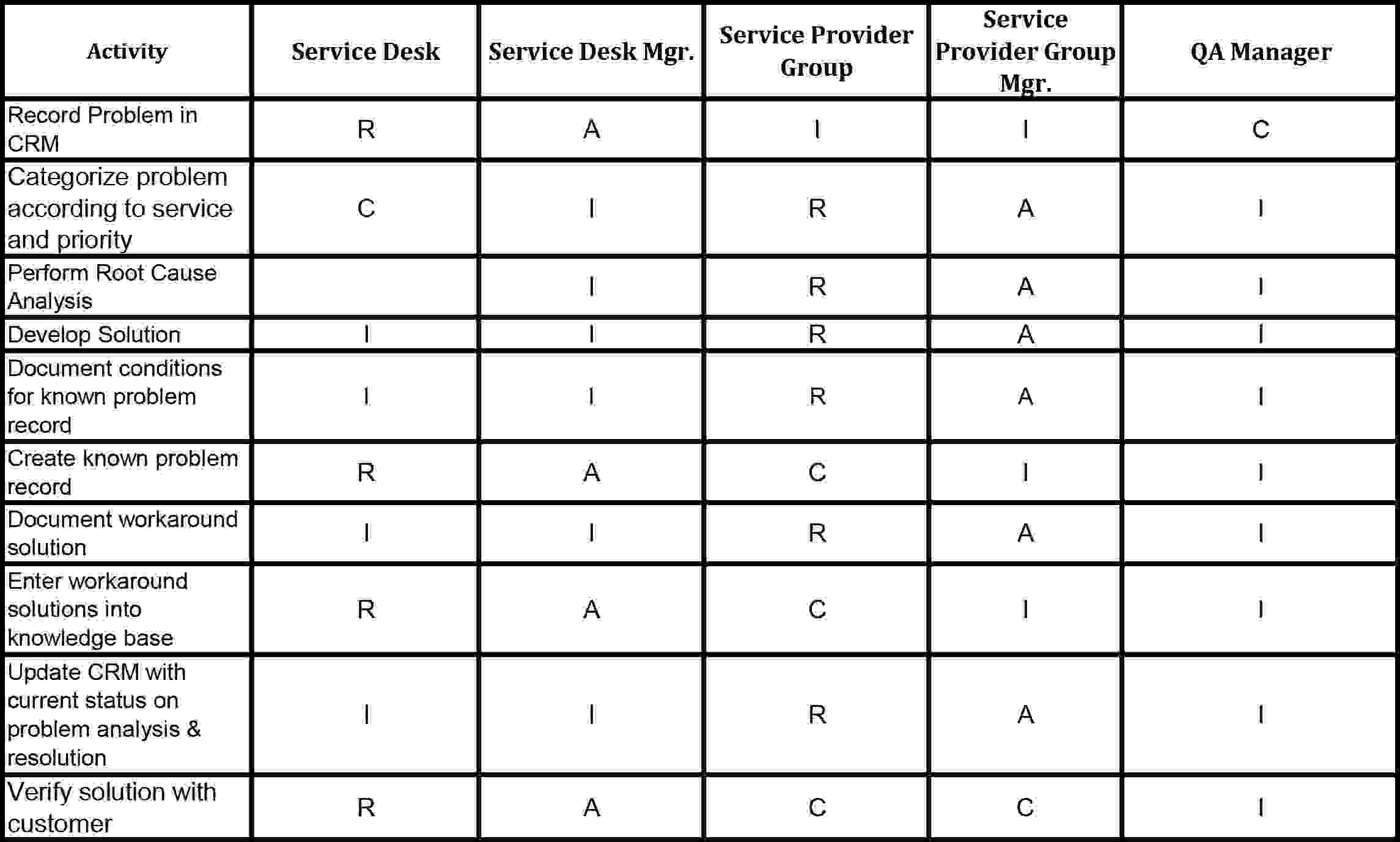
Define RACI Matrix/Roles and Responsibilities:
Service Desk Manager should be in direct communication with the Problem Manager, as he or she will likely be the first alerted when a cluster of Critical or High Priority incidents are opened.
The primary Activities/Responsibilities should be defined in Problem Management. The Problem Manager should be responsible to perform the assigned task (R), accountable to make certain work is assigned and performed (A), consulted about how to perform the task appropriately (C) and be informed about key events regarding the tasks (I)
Step 2: Target Root Cause Analysis:
A documented process for
Root Cause Analysis that describes what techniques will be used should be created. These can include brainstorming, Ishikawa diagrams or any other technique that successfully uncovers the underlying cause. This process should be the most suitable, and the group composed of representatives from any possible area of breakdown.
Step 3: Find a Workaround :
If Solution provider group is able to find the workaround then a problem becomes a “known error.”
The workaround should be communicated to all end-users who have submitted an incident/ incidents placed in a “resolved” status. Additionally, the known error and workaround should be published to the knowledge base for resolution at the
Service Desk and can be shared with all affected. Related incidents should be continued to open as reported and be linked to the problem record, but if the published workaround has been implemented with the end-user, the newly related incidents should be in a “resolved” state. This should stop SLA calculations against the incidents, but will not allow full closure until the problem is resolved and closed. Once the environment has calmed down and productivity restored to the end-users through the workaround, Problem Managers must decide if permanently fixing the root cause is economically viable or if the workaround should become permanent.
Step 4: Actions to be taken for handling problems:
One should either do nothing - if the business is not affected by problem, or if benefits are less than the cost of fixing problem
Or should deploy work around if determination of root cause exceeds the benefits.
Else determine root cause and fix problem if the benefit is worth fixing.
Focus on customers, not infrastructure. The tendency is to focus on the most troublesome infrastructure. However, the goal of effective
IT Service Management is to focus on customers.
Author : SiddharthPareek
Click Here for Service Management Course